Next:
Overall Performance Up:
Performance Evaluation Previous:
Hit Time
This section shows that our miss penalty is dominated by disk and network times. To better characterize the techniques that affect miss penalty, we break it down as:
Miss penalty = Fetch time + Replacement overhead + Conversion overhead
Here, fetch time is the average time to fetch a page from the server, replacement overhead is the average time to free a page frame in the client cache to hold a fetched page, and conversion overhead is the average time per fetch to convert fetched objects from their on-disk to their in-cache format (i.e., install them in the indirection table and swizzle their pointers).
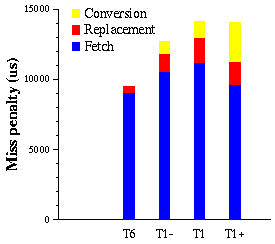
Figure 9 presents a breakdown of HAC's miss penalty for the static traversals. The miss penalty was measured for the experimental point where replacement overhead was maximal for each traversal. This point corresponded to hot traversals with cache sizes of 0.16 MB for T6, 5 MB for T1-, 12 MB for T1 and 20 MB for T1+.
Conversion overhead is the smallest component of the miss penalty for all
traversals but T1+, which we believe is not a realistic workload.
The conversion overhead grows with the quality of clustering because both
the number of installed objects per page and the number of swizzled pointers
per page increase. The conversion overhead is relatively low: it is 0.7%
of the fetch time for T6, 9% for T1-, and 10% for T1. Let us
compare this conversion overhead to that in QuickStore. QuickStore's conversion
overhead includes the time to process its mapping objects, and can easily
exceed HAC's conversion overhead when clustering is poor and mapping objects
are large. Furthermore, QuickStore's conversion overhead is much higher
than HAC's when it is not possible to map disk pages to the virtual memory
frames described by its mapping objects; the authors of [WD94]
present results that show an increase in the total time for a cold T1 traversal
of 38% in this case.
Figure 9 shows the overhead when replacement is performed in the foreground; it is 5% of the fetch time for T6, 12% for T1-, 16% for T1, and 17% for T1+. Since this overhead is much lower than the fetch time, HAC is able to perform replacement with no cost if the processor is idle waiting for the fetch reply; otherwise, the actual replacement cost will be between zero and the foreground replacement overhead reported in Figure 9.
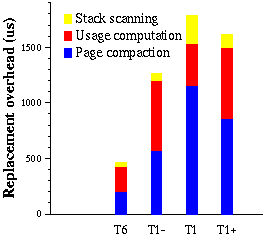
Figure 10 presents a breakdown of
the foreground replacement overhead for HAC. As the figure shows, replacement
overhead grows with the quality of clustering, except that it is lower
for T1+ than for T1. This happens mainly because the fraction
of a fetched page that survives compaction grows, causing an increase in
the page compaction time. The exception for T1+ occurs because
HAC tends to evict entire pages for traversals with extremely good clustering.
The cost of stack scanning is significantly lower than the cost of usage
computation and page compaction. However, it is high in traversal T1 (14%
of the total) because the OO7 traversals are implemented using recursion,
which results in large stack sizes; we expect the cost of stack scanning
to be lower for most applications.
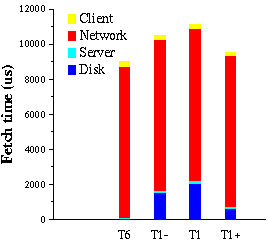
Figure 11 presents a breakdown of
the fetch time. The most important observation is that fetch time is completely
dominated by the time spent transmitting the fetch request and reply over
the network, and by the time spent reading pages from disk at the server.
The cost labeled client corresponds to the overhead of registering
pages in the client cache and server corresponds to the cache bookkeeping
cost at the server and the additional overhead to support transactions.
For most system configurations, the cost of foreground replacement and format conversions as a fraction of fetch time will be lower than the values we report. This is clearly true when a slower network is used, e.g., client and server connected by a wireless network or a WAN, but the use of a faster network could presumably increase the relative cost. We believe that the reduction in network time would be offset by the following factors. First, in our experimental configuration, the disk time is only a small fraction of the total fetch time because the hit rate in the server cache is unrealistically high; T1 has the lowest server cache hit rate and it is still 86%. In a configuration with a realistic hit rate of 23% (measured by Blaze [Bla93] in distributed file systems), the foreground replacement overheads in T1- and T1 would be 11% and 16% of the disk time alone. Second, our server was accessed by a single client; in a real system, servers may be shared by many clients, and contention for the servers' resources will lead to even more expensive fetches. Third, our client machine is a DEC 3000/400 with a 133 MHz Alpha 21064 processor, which is slow compared to more recent machines; our overheads will be lower in today's machines. For example, we reran the experiments described in this section on a 200 MHz Intel Pentium Pro with a 256 KB L2 cache. The conversion overheads on this machine relative to the overheads on the Alpha workstation were 33% for T1- and 42% for T1; the foreground replacement overheads were 75% for T1- and 77% for T1. Note that the speedup of the replacement overhead should be larger in a machine with a larger second level cache.
Next: Overall Performance Up: Performance Evaluation Previous: Hit Time
Miguel Castro, Atul Adya, Barbara Liskov, and Andrew Myers