Figure 1: Medical Study Scenario
Let us consider two examples for which a decentralized model of information flow is helpful -- the medical study and the bank, depicted in Figures 1 and 2. The scenarios place somewhat different demands on the information flow model. They demonstrate that our approach permits legitimate flows that would not be allowed with conventional information flow control, and that it is easy to determine that information is not being leaked.
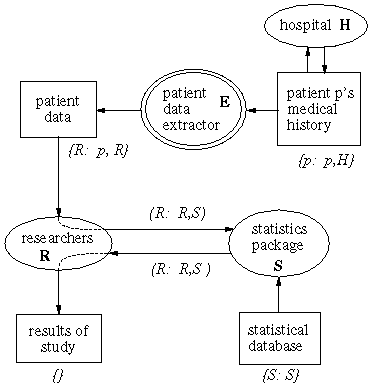
In the figures, an oval represents a principal within the system, and is labeled with a boldface character that indicates the authority with which it acts. For example, in the medical study (Figure 1), the important principals are the patient, p, a group of researchers, R, the owners of a statistical analysis package, S, and a trusted agent, E. Arrows in the diagrams represent information flows between principals; square boxes represent information that is flowing, or databases of some sort.
Each principal can independently specify policies for the propagation of its information. These policies are indicated by labels of the form {O: R}, meaning that owner O allows the information to be read by readers R, where O is a principal and R is a set of principals. The owner is the source of the information and has the ability to control the policy for its use. For example, in the medical study example, the patient's medical history may be read only by principals with the authority to act on behalf of the patient p and the hospital H.
In the diagrams, double ovals represent trusted agents that declassify information (for example, E in the medical study). These agents have the authority to act on behalf of a principal in the system, and may therefore modify the policies that have been attached to data by that principal. One goal of these two examples is show how our approach limits the trust that is needed by participants in the system; the double ovals identify the places where special trust is needed.
Figure 1: Medical Study Scenario
The medical study example shows that it is possible to give another party private information and receive the results of its computation while remaining confident that the data given to it is not leaked. The purpose of the study is to perform a statistical analysis of the medical records of a large number of patients. Obviously, the patients would like to keep specific details of their medical history private. The patients give permission to the researchers performing the study to use their medical data to produce statistics, with the understanding that their names and other identifying information will not be released. Thus, the patients put some trust in the patient data extractor, E, which delivers to the researchers a suitably abridged version of the patient records. The data extractor has the authority to act for the patient (p), so it can replace the patient's policy {p: p,H} with the researcher-controlled policy, {R: p,R}, which allows the extracted data to be read by the researchers and by the patient.
The researchers would like to use a statistical analysis package that they have obtained from another source, but the patients and researchers want the guarantee that the analysis package will not leak their data to a third party. To accomplish this, the researchers relabel the patient data with {R: R,S}. The analysis package is able to observe but not to leak the relabeled data since S is only a reader, not an owner.
The analysis package performs its computations, using the patient data, now labeled {R: R,S}, and its own statistical database, labeled {S: S}. The writers of the analysis package would also like some assurance that their statistical database is not being leaked to the researchers. The result of the computation must retain the policies of both R and S, and therefore acquires the joint label {R: R,S; S: S}. This label only allows flows to the principal S, since S is the only principal in both reader sets. The analysis package then explicitly declassifies the result of the computation, changing the label to {R: R,S} so the researchers can read it. Note that since the analysis package can declassify the analysis result, it is not forced to declassify all information extracted from the statistical database, which would probably require more careful analysis of the analysis code to show that the database contents were not leaked.
Finally, the researchers may declassify the result of their study, changing the label {R: R,S} to the unrestricted label {}. This change allows the general public to see their results, and is acceptable as long as there are so many patients in the study that information about individual patients cannot be extracted from the final result.
This example uses declassification in four places. Each time, declassification takes place according to the simple rule that a principal may modify its own flow policies. Conventional information flow control has no notion of declassification within the label system, and therefore, cannot model this example.
The bank scenario is illustrated in Figure 2. A bank serves many
customers, each of whom would like to keep his data
safe from other customers and non-customers.
In addition, the bank stores private
information, such as its current assets and investments, that it would
like to keep safe from all customers and non-customers.
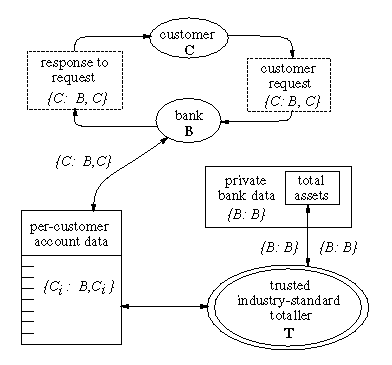
Figure 2: Bank Scenario
The bank receives periodic requests from each customer, e.g., to withdraw or deposit money. Each request should be able to observe only information that is owned by that customer, and none of the bank's private data. The bank is better than real banks in that it allows customers to control dissemination of their account information; each customer has a distinct information flow policy for his account information, which prevents the bank from leaking the information to another party. The customer's request, the account itself, and the bank's response to the request are all labeled {C: B,C}, allowing the bank to read the information but not to control it. However, the bank's private database, including its record of total assets, is most naturally labeled {B: B}.
To keep the total assets up to date, information derived from the customer's request must be applied to the total assets. To make this possible, the customer places trust in the totaller, T, a small piece of the bank software that acts with the authority of both the customer and the bank, and therefore can declassify the amount of the customer request in order to apply it to the total asset record. Conceivably, the totaller is a certified, industry-standard component that the customer trusts more than the rest of the bank software. Another reasonable model is that the totaller is part of an audit facility that is outside the bank's control.
Next: 3 Decentralized Information Flow Up: A Model for Decentralized Previous: 1 Introduction
Andrew C. Myers, Barbara Liskov